فرهیختگان: صنعت نظرسنجی از دهههای نخست قرن بیستم بهعنوان یکی از مهمترین و کارآمدترین ابزارهای سنجش افکار عمومی در آمریکا ظهور کرد و درطول این سالها تا امروز، فرازونشیبهای فراوانی را پشتسر گذاشته است. این مسیر با موفقیتها و شکستهایی همراه بوده که هریک بهشکلی در انباشت دانشی و تکامل این حوزه نقش داشتهاند. بااینحال به نظر میرسد این صنعت پس از انتخابات ۲۰۱۶ در آمریکا وارد مرحلهای پرچالش و متفاوت شده است؛ مرحلهای که مشخص شدن نتیجه نهایی انتخابات ۲۰۲۴ آمریکا بار دیگر نشان داد چالشهای آن همچنان پابرجایند.
اولین بحران بزرگ در نظرسنجیهای انتخاباتی، به انتخابات ریاستجمهوری ۲۰۱۶ برمیگردد. در آن سال، هیلاری کلینتون در آرای ملی و ایالتهای چرخشی اصلی از دونالد ترامپ جلو بود؛ اما درنهایت، ترامپ در آرای الکترال پیروز شد. همین اتفاق با شکلی دیگر، در انتخابات ۲۰۲۰ نیز رخ داد. در نظرسنجیهای پیش از انتخابات ۲۰۲۰ پیشبینی میشد که جو بایدن ۵۴ درصد آرای ملی را کسب کند و در تمام ایالتهای چرخشی با اختلاف برنده شود. اما نتیجه نهایی متفاوت بود؛ بایدن با اختلافی اندک در آرای الکترال پیروز شد، درحالیکه در آرای ملی، بزرگترین اشتباه نظرسنجیها طی چهاردهه رقم خورد. این اشتباهها نشان داد بسیاری از شرکتهای نظرسنجی، میزان حمایت از دموکراتها را بیش از حد تخمینزدهاند. بحثهای گستردهای درباره این خطاها شکل گرفت و راهحلهای متعددی نیز ارائه شد. بااینحال، همانطور که خواهیم دید، این مشکلات همچنان در سال ۲۰۲۴ ادامه یافتهاند.
برای درک بهتر دلایل خطا در نظرسنجیها و تلاشهایی که برای رفع آنها صورت گرفته، ابتدا باید با انواع خطاهای موجود در نظرسنجیها و مخصوصاً نظرسنجیهای مربوط به پیشبینی انتخابات بیشتر آشنا شویم. سؤال این است که چرا خطاها در برآورد آرای ترامپ مکرراً در سالهای ۲۰۱۶، ۲۰۲۰ و حالا در ۲۰۲۴ تکرار شده و همچنان پابرجایند؟
مراکز نظرسنجی معمولاً برای انجام نظرسنجی یک نمونه تصادفی حدود هزار نفری (در برخی موارد بیشتر و کمتر) از جمعیت هدف را انتخاب میکنند و با افراد موجود در نمونه با درنظر گرفتن میزانی خطا (خطا بسته به حجم نمونه متغیر است؛ ولی مقداری حدود 2-4 درصد است) به تخمین نظرات جمعیت هدف میپردازند. خطایی که در این مرحله ممکن است ایجاد شود بهعنوان خطای نمونهگیری محاسبه میشود. وجود خطای نمونهگیری طبیعی است، زیرا کل جامعه هدف در دسترس نیست و با یک نمونه نسبتاً کوچک، ویژگیهای جامعه هدف تخمینزده میشود. بنابراین خطای نمونهگیری تا زمانی که کل جامعه را سرشماری نکنیم، همیشه وجود دارد.
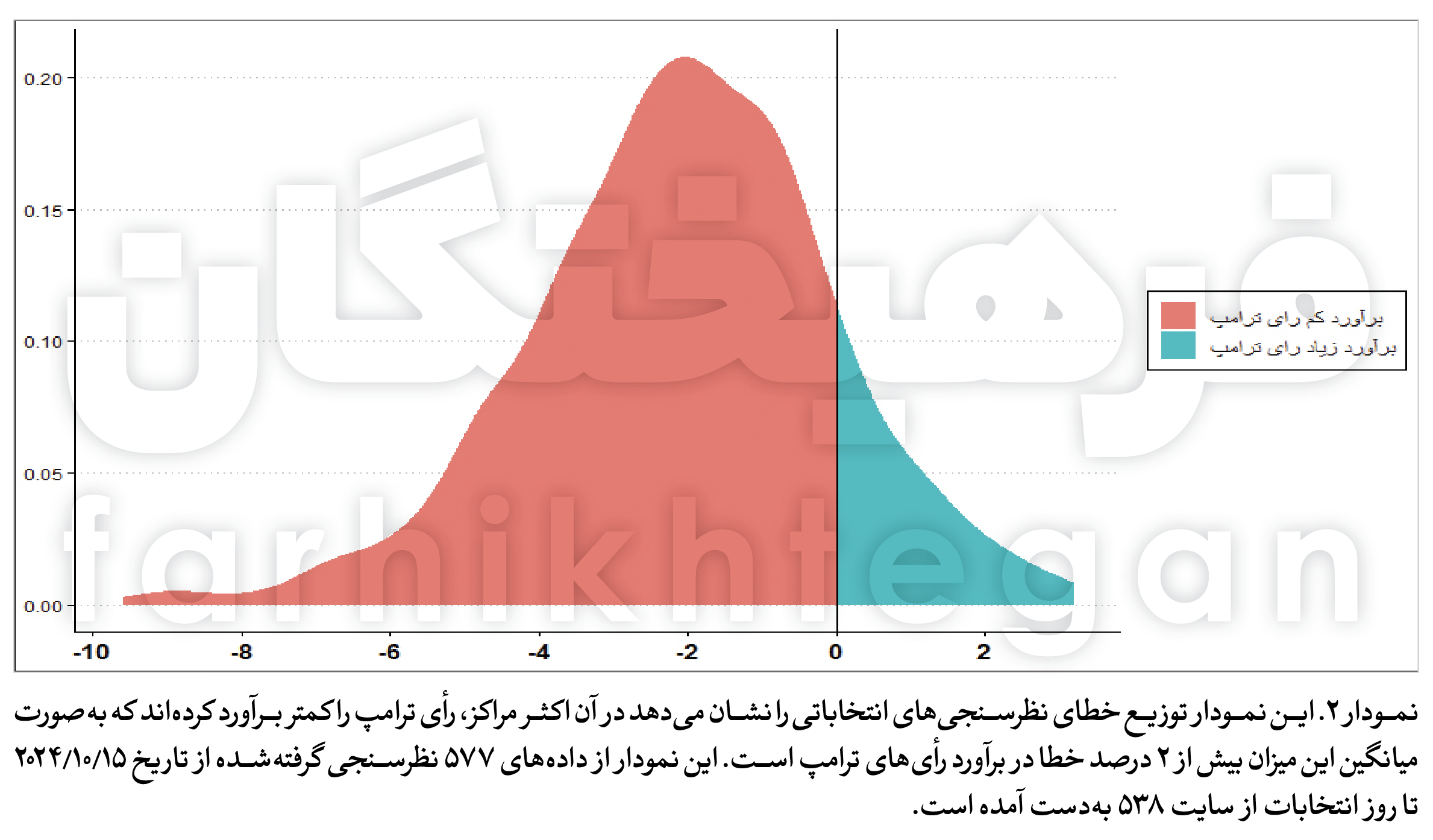
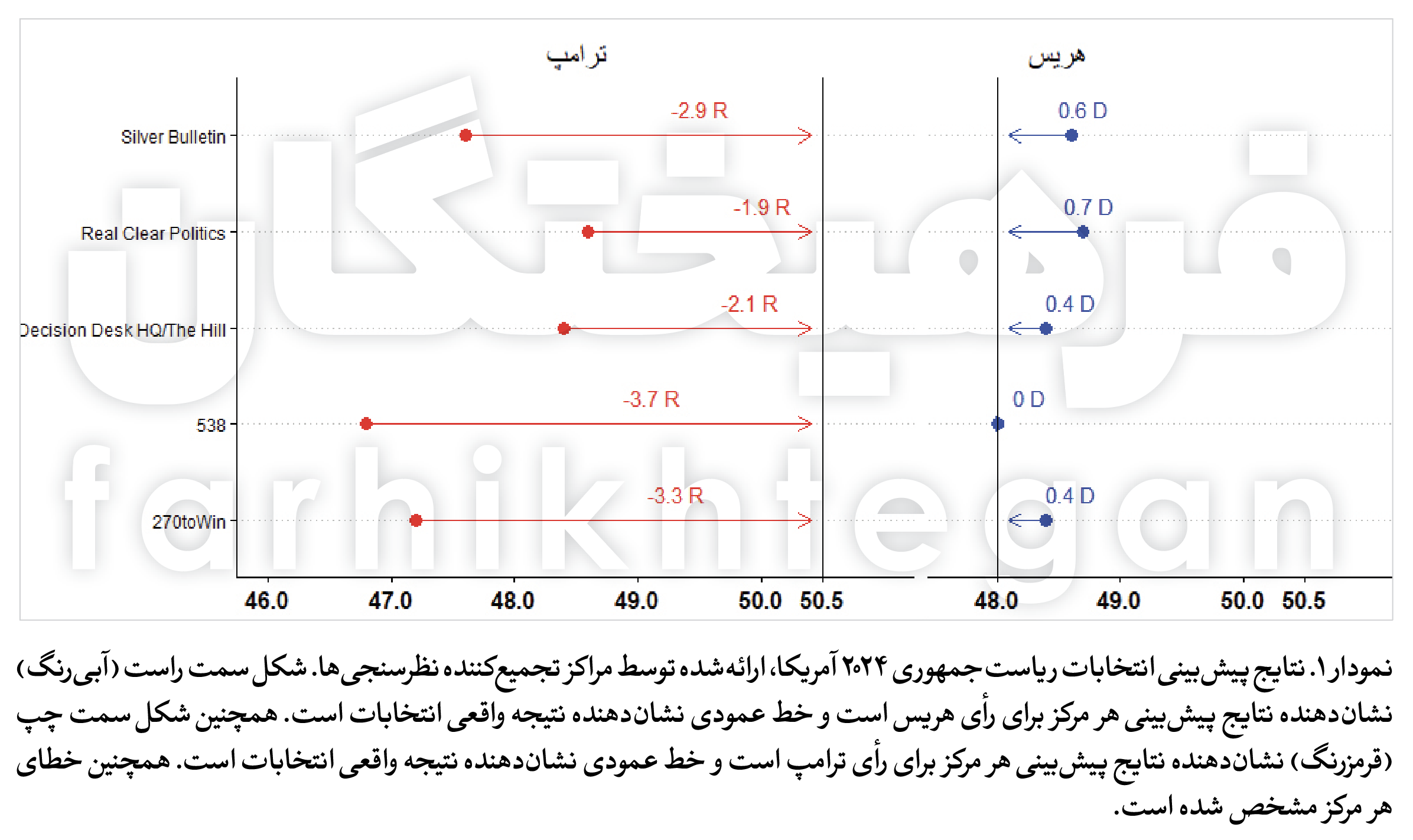{kind=link}
از طرفی همه افراد انتخابشده در نمونه، به سؤالات نظرسنجی پاسخ نمیدهند یا ناقص پاسخ میدهند. این عدم پاسخ، سبب ایجاد خطای «بیپاسخ» میشود. طبیعی است هرچه میزان پاسخ ندادن بیشتر باشد، خطای بیپاسخ بیشتر است. این خطا میتواند بسیار خطرناکتر از خطای نمونهگیری باشد. فرض کنید در یک پرسشنامه انتخاباتی خطای بیپاسخ وجود داشته باشد و این عدم پاسخ، تصادفی نباشد و یک یا چند بخش خاص از جامعه تمایلی به پاسخ نداشته باشند. در این صورت تخمین حاصل از پرسشنامه دارای خطاست، چون پیشبینی انجامشده، بخش خاصی از جامعه را شامل نمیشود که ممکن است نظرات خاصی هم داشته باشند. این خطا وقتی با موضوع «میزان رأی به نامزدها در انتخابات» همراه میشود، مشکل دیگری نیز ایجاد میکند، زیرا مشخص نیست افرادی که پاسخ ندادهاند کسانیاند که در انتخابات شرکت میکنند یا خیر؟ بنابراین ابتدا نیاز است تشخیص دهیم چه تعداد از کسانی که در گروه افراد بیپاسخند، اساساً در انتخابات نیز شرکت نخواهند کرد. درنتیجه مسئله نحوه و مدلسازی شرکت در انتخابات و میزان نرخ مشارکت در انتخابات هم برای پوشش این خطا دارای اهمیت است.
مسئله آخری که بیشتر نظرسنجیهای انتخاباتی با آن مواجه میشوند، این است که ممکن است نظرات افراد حاضر در نمونه، بعد از نظرسنجی تغییر کند یا حتی ممکن است این افراد نظرات و پاسخهایی نادرست و بدونصداقت بیان کنند، بنابراین پیشبینی انتخابات با استفاده از نظرسنجیها شامل چالشهای زیادی است و در عمل فراتر از یک نمونهگیری ساده است که معمولاً در کتابهای درسی آمار به آن اشاره میشود.
متن کامل گزارش حمیدرضا توکلی، پژوهشگر مرکز تحلیل اجتماعی متا مرکز رشد دانشگاه امام صادق(ع) را در روزنامه فرهیختگان بخوانید.